 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
以下描述适用于适用哪个数据挖掘算法:如果一个样本在特征空间中的N个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别?()
A.KNN,K最近邻算法
B.神经网络(NeuralNet)
C.支持向量机SVM
D.决策树(DecisionTree)
提问人:网友肖文娟
发布时间:2022-01-07
题目内容
(请给出正确答案)
A.KNN,K最近邻算法
B.神经网络(NeuralNet)
C.支持向量机SVM
D.决策树(DecisionTree)
 更多“以下描述适用于适用哪个数据挖掘算法:如果一个样本在特征空间中…”相关的问题
更多“以下描述适用于适用哪个数据挖掘算法:如果一个样本在特征空间中…”相关的问题
试设计一个算法,利用T公司提供的m个补丁程序,将原软件修复成一个没有错误的软件,并使修复后的软件耗时最少.
算法设计:对于给定的n个错误和m个补丁程序,找到总耗时最少的软件修复方案.
数据输入:由文件input.txt提供输入数据.文件第1行有2个正整数n和m,n表示错误总数,m表示补丁总数(1≤n≤20,1≤m≤100).接下来m行给出了m个补丁的信息.每行包括一个正整数,表示运行补丁程序i所需时间以及2个长度为n的字符串,中间用个空格符隔开.在第1个字符串中,如果第k个字符bk为“+”,则表示第k个错误属于B1[i],若为“-”,则表示第k个错误属于B2[i],若为“0”,则第k个错误既不属于B1[i]也不属于B2[i],即软件中是否包含第k个错误并不影响补丁i的可用性.在第2个字符串中,如果第k个字符bk为“+”,则表示第k个错误属于F1[i],若为“-”,则表示第k个错误属于F2[i],若为“0”,则第k个错误既不属于F1[i]也不属于F2[i],即软件中是否包含第k个错误不会因使用补丁i而改变.
结果输出:将总耗时数输出到文件output.txt.如果问题无解,则输出0.

以下对学籍管理系统的特征描述中,错误的是()。
A.提高学籍档案的管理效率
B.以数据库和数据处理为基础
C.能向学校的有关部门提供所需信息
D.完全取代人工操作
以下对学生选课管理系统的特征描述中,错误的是()。
A.提高学校的教学管理效率
B.以数据库和数据管理为基础
C.能够向学校的教学部门提供所需信息
D.可以完全取代人工操作
(1)n∈set(n);
(2)在n的左边加上一个自然数,但该自然数不能超过最近添加的数的一半:
(3)按此规则进行处理,直到不能再添加自然数为止.
例如,set(6)={6,16,26,126,36,136}.半数集set(6)中有6个元素.注意,该半数集不是多重集.集合中已经有的元素不再添加到集合中.
算法设计:对于给定的自然数n,计算半数集set(n)中的元素个数.
数据输入:输入数据由文件名为input.txt的文本文件提供.每个文件只有一行,给出整数n(0<n<1000).
结果输出:将计算结果输出到文件output.txt.输出文件只有一行,给出半数集set(n)中的元素个数.

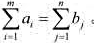 .从第i个仓库运送每单位货物到第j个零售商店的费用为cij试分别设计一个将仓库中所有货物运送到零售商店的最优和最差运输方案,即使总运输费用最少或最多.
.从第i个仓库运送每单位货物到第j个零售商店的费用为cij试分别设计一个将仓库中所有货物运送到零售商店的最优和最差运输方案,即使总运输费用最少或最多.算法设计:对于给定的m个仓库和n个零售商店间运送货物的费用,计算最优运输方案和最差运输方案.
数据输入:由文件input.txt提供输入数据.文件的第1行有2个正整数m和小,分别表示仓库数和零售商店数.接下来的一行中有m个正整数ai(1≤i≤m),表示第i个仓库有ai个单位的货物.再接下来的一行中有n个正整数bj(1≤j≤n),表示第j个零售商店需要bj个单位的货物.接下来的m行,每行有n个整数,表示从第i个仓库运送每单位货物到第j个零售商店的费用cij.
结果输出:将计算的最少运输费用和最多运输费用输出到文件output.txt.


(1)该算法的功能是什么?
(2)若待排序数据序列为(10,20,30,40,50,60),给出每次while执行的结果序列。
(3)若待排序数序列为(60,50,40,30,20,10),给出每次while执行的结果序列。




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 














