 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
HDFS默认的一个块大小是
A.64MB
B.8KB
C.16KB
D.32KB
提问人:网友qz4a506
发布时间:2022-01-07
题目内容
(请给出正确答案)
A.64MB
B.8KB
C.16KB
D.32KB
 更多“HDFS默认的一个块大小是”相关的问题
更多“HDFS默认的一个块大小是”相关的问题
A、200
B、40000
C、400
D、1200
B、存储客户端上传的数据的数据块
C、一个DataNode上存储的所有数据块可以有相同的
D、响应客户端的所有读写数据请求,为客户端的存储和读取数据提供支撑
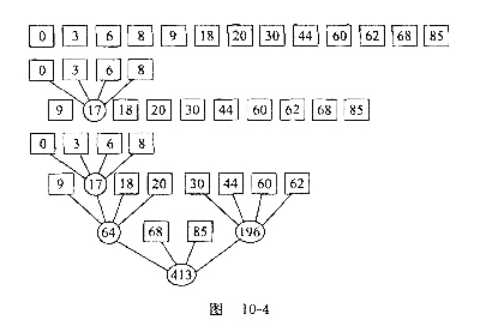
(1)若将线性索引常驻内存,文件中最多可以存放多少个记录?(每个索引项8字节,其中关键码4字节,地址4字节)
(2)如果使用二级索引,第二级索引占用1024字节(有128个索引项,每个索引项8字节),这时文件中最多可以存放多少个记录?
B、Map任务从其他数据节点读取数据。可以从JobTracker的map任务细节信息和任务运行尝试中找到输入块的位置。如果输入块的位置不是任务执行的节点,那就不是本地数据了
C、源文件的大小远小于HDFS的块的大小。这意味着任务的开启和停止要耗费更多的时间,就没有足够的时间来读取并处理输入数据
D、一个节点的本地磁盘或磁盘控制器运行在降级模式中,读取写入性能都很差。这会影响某个节点,而不是全部节点
A、hdfs dfs -put file.txt /path
B、hadoop dfs -put /path file.txt
C、hdfs dfs -put /path file.txt
D、hdfs fs -put file.txt /path
A、HBase是针对谷歌BigTable的开源实现,是高可靠、高性能的图数据库
B、HBase是一种NoSQL数据库
C、在向数据库中插入记录时,HBase和关系数据库一样,每次都是以“行”为单位把整条记录插入数据库
D、HBase数据库表可以设置该表任意列作为索引
A、hadoop fs -mkdir -p /test/dir
B、hadoop dfs -mkdir /test/dir
C、hdfs fs -mkdir -p /test/dir
D、hdfs dfs *mkdir -p /test/dir




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 














