 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
下面关于信息熵的描述中错误的是:
A.热力学中的热熵是表示分子状态混乱程度的物理量。信息熵概念的提出受到了热力学中的热熵的概念的启发
B.信息熵由Shannon提出,信息熵的概念可以用来描述信源的不确定度
C.信息熵是通信领域的概念,和机器学习以及深度学习无关
D.在深度学习中,经常使用交叉熵来表征两个变量概率分布P, Q(假设P表示真实分布, Q为模型预测的分布)的差异性。
提问人:网友lanpishu
发布时间:2022-01-07
题目内容
(请给出正确答案)
A.热力学中的热熵是表示分子状态混乱程度的物理量。信息熵概念的提出受到了热力学中的热熵的概念的启发
B.信息熵由Shannon提出,信息熵的概念可以用来描述信源的不确定度
C.信息熵是通信领域的概念,和机器学习以及深度学习无关
D.在深度学习中,经常使用交叉熵来表征两个变量概率分布P, Q(假设P表示真实分布, Q为模型预测的分布)的差异性。
 更多“下面关于信息熵的描述中错误的是:”相关的问题
更多“下面关于信息熵的描述中错误的是:”相关的问题
A、从信息论的角度来看,压缩就是去掉信息中的冗余,即保留不确定的信息,去除确定的信息(可推知的)。
B、根据解码后数据与原始数据是否完全一致,数据压缩可以分为两大类:有损压缩和无损压缩。
C、图像信息之所以能进行压缩,是因为图像本身通常存在很大的冗余量。
D、在有损压缩中,解压缩后重构的数据是对原始对象的完整复制。
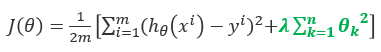 则下列说法正确的有
则下列说法正确的有
A、等号右边第一项的目标是使模型能更好地拟合训练数据
B、等号右边第二项是正则化项,目的是控制过拟合现象
C、λ 是正则化参数(regularization parameter),用于控制等号右边两项的平衡
D、过拟合是指学习到的模型在训练集上也许误差较小,但是对于测试集中之前未见样本的预测却未必有效。或者通俗地说,模型过度学习了训练数据。
A、sigmoid函数
B、阶跃函数
C、tanh函数
D、relu函数
A、感知机由Rosenblatt于1957年提出,是神经网络的基础
B、感知机是二分类的线性分类模型,属于有监督学习算法
C、感知机是二分类的线性分类模型,属于无监督学习算法
D、感知机的预测是用学习得到的感知机模型对新的实例进行预测的,因此属于判别模型
A、程序最后两行的计算结果是相等的
B、程序最后两行的计算结果是不相等的
C、程序最后两行的的目的是计算相对熵,其是交叉熵与信息熵的差值
D、程序的目的是计算相对熵,其不具备对称性

A、交叉熵
B、联合熵
C、互信息
D、相对熵
A、反向传播算法的学习过程由正向传播过程和反向传播过程组成,不存在迭代过程
B、在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层
C、如果经过正向传播,在输出层得不到期望的输出值,则利用输出与期望计算目标函数(损失函数),转入反向传播
D、反向传播需要逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯度,作为修改权值的依据。在机器学习中,训练数据通常是给定和固定的,而权重参数等是作为变量并进行更新的
A、最后一行是计算p和q之间的KL散度
B、最后一行是计算p和q之间的JS散度
C、最后一行是计算p和q之间的条件熵
D、最后一行是计算p和q之间的交叉熵




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 














