 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
以下关于drop_duplicates函数的说法中错误的是()。
A.仅对DataFrame和Series类型的数据有效
B.仅支持单一特征的数据去重
C.数据重复时默认保留第一个数据
D.该函数不会改变原始数据排列
提问人:网友orc1982
发布时间:2022-01-07
题目内容
(请给出正确答案)
A.仅对DataFrame和Series类型的数据有效
B.仅支持单一特征的数据去重
C.数据重复时默认保留第一个数据
D.该函数不会改变原始数据排列
 更多“以下关于drop_duplicates函数的说法中错误的是(…”相关的问题
更多“以下关于drop_duplicates函数的说法中错误的是(…”相关的问题
B.当创建的函数没有任何参数时 , 可以省略函数名后的圆括号
C.当函数需要返回值时 , 需要使用 return 语句
D.在一个函数内部可以存在另一个函数的声明,称为嵌套函数
B.盘坐中,两膝如果高于骨盆,需要垫高臀部
C.冥想练习中,非常重要是,保持脊柱正直
D.脚踝、膝关节有伤痛、不适的人群,可以坐在椅子上练习
A、离差标准化简单易懂,对最大值和最小值敏感度不高
B、标准差标准化是最常用的标准化方法,又名零一均值标准化
C、小数定标标准化实质上就是将数据按照一定的比例缩小
D、多个特征的数据的K-Means聚类不需要对数据进行标准化
A、null 和notnull可以对缺失值进行处理
B、dropna方法既可以删除观测记录,亦可以删除特征
C、fillna方法中用来替换缺失值的值只能是数据框
D、pandas库中的interpolate模块包含了多种插值方法
A、pandas没有做哑变量的函数
B、在不导入其他库的情况下,仅仅使用pandas就可实现聚类分析离散化
C、pandas可以实现所有的数据预处理操作
D、cut函数默认情况下做的是等宽法离散化
A、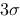 原则利用了统计学中小概率事件的原理
原则利用了统计学中小概率事件的原理
B、使用箱线图方法时要求数据服从或近似服从正态分布
C、基于聚类的方法可以进行离群点检测
D、基于分类的方法可以进行离群点检测
A、经过该方法处理后的数据均值为0,标准差为1
B、可能会改变数据的分布情况
C、Python中可自定义该方法实现函数: def StandardScaler(data): data = (data - data.mean()) / data.std() return data
D、计算公式为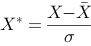
A、sklearn全称为 scikit-learn
B、sklearn 在官网被分为7个大块
C、sklearn 的聚类算法几乎都已经放在cluster 模块中了
D、sklearn 需要 NumPy和SciPy库的支持
A、fit在转换器中起到的作用为训练模型
B、fit在转换器中起到的作用为生成规则
C、transform 在转换器中起到的作用为应用规则
D、fit_transform是fit和transform的结合




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 














