 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
处理冲突实际就是为了产生冲突的地址寻找下一个散列地址。
提问人:网友reed591
发布时间:2022-01-06
题目内容
(请给出正确答案)
 更多“处理冲突实际就是为了产生冲突的地址寻找下一个散列地址。”相关的问题
更多“处理冲突实际就是为了产生冲突的地址寻找下一个散列地址。”相关的问题
B、两个元素的关键码值不同,而非关键码值相同
C、不同关键码值对应到相同的存储地址
D、装载因子过大,数据元素过多
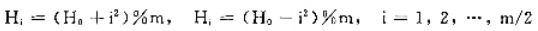
其中,H0是第一次求得的散列地址,Hi是第i次求得的散列地址,m是散列表的大小。
(1)相邻的地址Hi与Hi-1之间是什么关系?
(2)为保证散列地址序列的地址不会循而往复地重迭,m应设为什么数?装填因子α应如何取值?
(3)为保证在删除时不中断搜索链,可对被删记录做逻辑删除。为此,每个散列地址有3个状态,除了Active(正在使用)和Deleted(删除)状态外,还应有一个什么状态?
(1)设计用分离的同义词子表组织的开散列表的类。
(2)设计在做列表中搜索具有指定关键码值的表项的算法。
(3)设计在散列表中删除具有指定关键码值的表项的算法。
(4)设计在散列表中插人具有指定关键码值的表项的算法。
(5)设计由一组关键码值建立散列表的算法。
(6)设计输出散列表的算法。
(7)求搜索成功时的平均搜索长度的算法。
(8)求搜索不成功时的平均搜索长度的算法。
有一个散列表,共有N个槽,采用双散列探查的闭散列方法解决冲突。经过一系列插入操作,当前散列表中有M个元素,负载因子a为0.1,即M/N=a=0.1。假设M,N都非常大,并且双散列探查方法近使得每一次探查的位置,可以近似为均匀分布(即等概率地探查每个槽)。 当前对于某个关键码,近似估算不成功检索的平均检索长度()请保留2位小数 There is a hash table of size N, using closed hashing implemented by double hashing retrieval to solve conflicts. After a series of insert operations, there are M elements in the table, the load factor a is 0.1, which means M/N = a = 0.1. We assume that m and n are both very big. And the probabilities of all the position to be probed is approximately evenly distributed because of double hashing retrieval. Now for some key value, approximately estimating the average length of failed retrieval (). Please keep two places of decimal.




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 










