 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
变量是我们用来存储数值用的,你可以把它当做一个容器。比如:a=100,我们就把100这个数值存储在a里面,则a这个时候就是一个变量。
提问人:网友jiankelaodi
发布时间:2022-01-07
题目内容
(请给出正确答案)
 更多“变量是我们用来存储数值用的,你可以把它当做一个容器。比如:a…”相关的问题
更多“变量是我们用来存储数值用的,你可以把它当做一个容器。比如:a…”相关的问题
A、VIF≥10
B、VIF≤0
C、VIF≤1
D、VIF<10<br>

及AR(1)模式

于是科克伦和奥克特推荐如下步腺来估计ρ。
(1)用通常的OLS方法估计方程①并得到残差ut。顺便指出,你可以在模型中包含不止一个X变量。
(2)利用第1步得到的残差做如下回归:

这是方程②在实证中的对应表达式。
(3)利用方程③中得到的 ,估计广义差分方程(129.6)。
,估计广义差分方程(129.6)。
(4)由于事先不知道方程③中得到的 是不是ρ的最佳估计值,所以把第3步中得到的
是不是ρ的最佳估计值,所以把第3步中得到的 值代入原回归①,并得到新的残差解
值代入原回归①,并得到新的残差解 为
为


(5)现在估计如下回归

它类似于方程③,并给出p的第二轮估计值。由于我们不知道p的第二轮估计值是不是真实p的最佳估计值,所以我们进入第三轮估计,如此等等。这正是科克伦-奧克特程序被称为迭代程序的原因。我们该把这种(愉快的)轮回操作进行到什么程度呢?一般的建议是,当p的两个相邻估计值相差很小(比如不是0.01或0.005)时,便可停止迭代。在工资-生产率一例中,在停止之前约需要3次迭代。
a.利用科克伦-奥克特迭代程序,估计工资生产率回归(12.5.2)的p.在得到ρ的“最终”估计值之前需要多少次迭代?
b.利用a中得到的p的最终估计值,在去掉第一次观测和保留第一次观测的情况下,估计工资生产率回归。结果有何差异?
c.你认为在变换数据以解决自相关问题时保留第一次观测重要吗?
(i)变量phsrank表示一个人的高中百分位等级。(数字越大越好。比如90意味着, 你的排名比所在班级中90%的同学更高。)求出样本中phsrank的最小、最大和平均值。
(ii)在方程(4.26) 中增加变量phsrank, 并照常报告OLS估计值。phs rank在统计上显著吗?高中排名提高10个百分位点,能导致工资增加多少?
(iii)在方程(4.26) 中增加变量phs rank显著改变了2年制和4年制大学教育回报的结论了吗?请解释。
(iv)数据集包含了一个被称为id的变量。你若在方程(4.17)或(4.26)中增加id,预计它在统计上不会显著,解释为什么?双侧检验的p值是多少?
(i)变量phsrank表示一个人的高中百分位等级。(数字越大越好。比如90意味着,你的排名比所在班级中90%的同学更高。)求出样本中phsrank的最小、最大和平均值。
(ii)在方程(4.26)中增加变量phsrank,并照常报告OLS估计值。phsrank在统计上显著吗?高中排名提高10个百分位点,能导致工资增加多少?
(iii)在方程(4.26)中增加变量phsrank显著改变了2年制和4年制大学教育回报的结论了吗?请解释。
(iv)数据集包含了一个被称为id的变量。你若在方程(4.17)或(4.26)中增加id,预计它在统计上不会显著,解释为什么?双侧检验的p值是多少?
(i) 如果你利用一个容量为n的随机样本进行score。对voucheri的简单回归, 那么, 普通最小二乘估计量能给出教育券项目影响的一个无偏估计量吗?
(ii)假设你还可以搜集到一些诸如家庭收入、家庭结构(比如孩子是否与双亲住在一起)和父母的受教育水平等背景信息。为了得到教育券项目影响的无偏估计量,你需要控制这些因素吗?请解释。
(iii)你为什么应该在回归中包含这些家庭背景变量?有没有你不包含这些背景变量的情况呢?
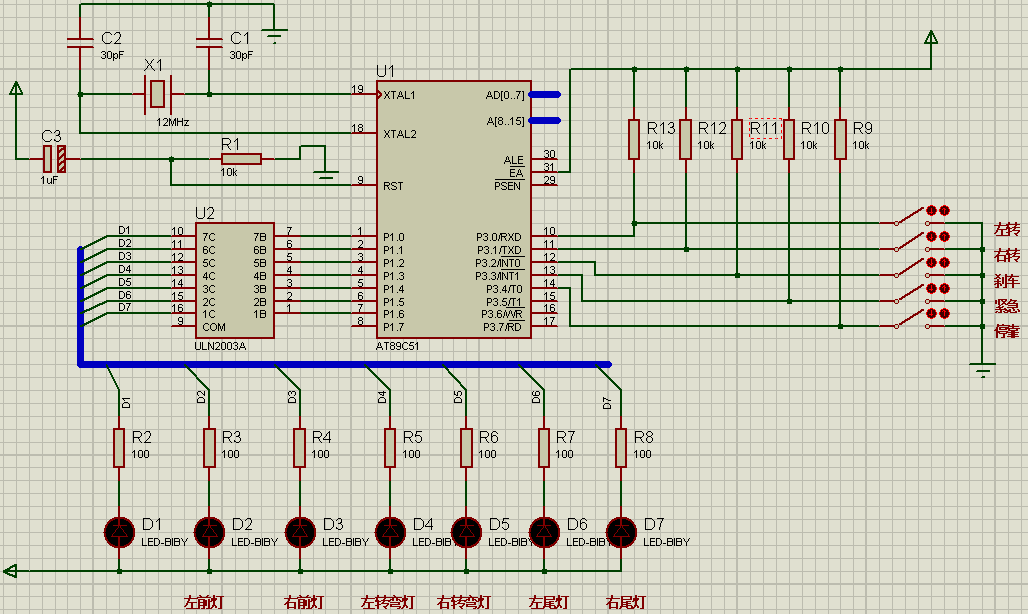
A、0xff 0xa2
B、0xfe 0x2a
C、0xfe 0xa2
D、0xef 0x2a
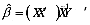
a.当x变量之间有完全共线性时,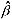 会发生什么情况?
会发生什么情况?
b.你怎样知道有没有完全共线性?




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 










