 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
Spark是一个专为大规模数据处理而设计的快速通用的计算引擎,官方支持Scala、Java、C、Python语言
提问人:网友logloveu
发布时间:2022-01-07
题目内容
(请给出正确答案)
 更多“Spark是一个专为大规模数据处理而设计的快速通用的计算引擎…”相关的问题
更多“Spark是一个专为大规模数据处理而设计的快速通用的计算引擎…”相关的问题
B.NoSQL数据库类型可以分为键值型NoSQL数据库,文档型NoSQL数据库,列存储型NoSQL数据库和图NoSQL数据库
C.Redis是单纯的内存数据库,不提供数据持久化功能,因此可靠性很低。
D.Spark分布式计算框架可以支持多种计算模式,包括批处理、流处理和SQL查询。
A、Flink是一行一行地处理数据
B、Flink可以支持毫秒级的响应
C、Flink只能支持秒级的响应
D、Flink支持增量迭代,具有对迭代进行自动优化的功能
 .m处理器问题要求的是
.m处理器问题要求的是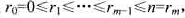 ,将数据包序列划分为m段:
,将数据包序列划分为m段:
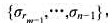 使
使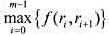 达到最小.式中,
达到最小.式中, 是序列
是序列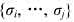 的负载量.
的负载量. 的最小值称为数据包序列
的最小值称为数据包序列 的均衡负载量.
的均衡负载量.
算法设计:对于给定的数据包序列,计算m个处理器的均衡负载量.
数据输入:由文件input.txt给出输入数据.第1行有2个正整数n和m.n表示数据包个数,m表示处理器数.接下来的1行中有n个整数,表示n个数据包的大小.
结果输出:将计算的处理器均衡负载量输出到文件output,txt,且保留2位小数.

A、云计算为这些海量、多样化的大数据提供存储和运算平台
B、大数据可以创造出巨大的经济和社会价值
C、云计算、大数据、物联网都离不开互联网
D、目前人工智能研究已经实现了通用人工智能




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 










