 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
下列关于自动编码器的损失函数的说法中正确的是
A.为了计算自动编码器的损失函数,需要用到样本的类别标签
B.自动编码器的损失函数主要是重构自身的误差,因此不会用到样本的类别标签
C.自动编码器由于是无监督模型,所以不存在损失函数的问题
D.自动编码器需要利用到损失函数来反向传播,以更新模型的参数
提问人:网友chao_wg
发布时间:2022-01-07
题目内容
(请给出正确答案)
A.为了计算自动编码器的损失函数,需要用到样本的类别标签
B.自动编码器的损失函数主要是重构自身的误差,因此不会用到样本的类别标签
C.自动编码器由于是无监督模型,所以不存在损失函数的问题
D.自动编码器需要利用到损失函数来反向传播,以更新模型的参数
 更多“下列关于自动编码器的损失函数的说法中正确的是”相关的问题
更多“下列关于自动编码器的损失函数的说法中正确的是”相关的问题
A、自动编码器常用于做生成模型
B、自动编码器不需要任何训练数据,完全是自动编码
C、自动编码器可以用于数据的降维处理
D、自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用
A、使用自动编码器提取特征,并与有监督学习模型使用。因为监督学习通常的标注数据较少
B、重构自身而已
C、可以用许多无标签的数据学习得到数据通用的特征表示
D、其它答案都不对
A、变分自编码器通常采用最大对数似然来学习得到模型的参数
B、变分编码器实际上是在优化数据的对数似然的下界,并求解参数
C、变分自编码器的训练过程中用到了KL散度的计算
D、其它答案都不对
A、变分自编码器(Variational Autoencoders,VAE)通常假设潜在变量 服从某种先验分布(如高斯分布)
B、模型训练完毕后,可以从这种先验分布中采样得到潜在变量 。并在解码器中通过潜在变量得到 新的样本
C、VAE在自动编码机基础上加入了随机因子,这样就可以从该模型中采样得到新的数据
D、其它答案都不对
A、变分自编码器在生成数据阶段只需要解码器
B、变分自编码器在生成数据阶段只需要编码器
C、变分自编码器在生成数据阶段需用用到采样技术
D、变分自编码器既然是无监督模型,因此不需要进行训练
A、判别式模型只是对给定的样本进行分类,不关心数据如何生成
B、生成式模型主要回答的问题是,根据生成假设,哪个类别最有可能生成这个样本?
C、生成式模型不能用于判别
D、其它答案都不对
A、判别器和生成器的参数在每次迭代时,都要同时更新参数
B、在训练判别器时,生成器参数被固定
C、在训练生成器时,判别器的参数被固定
D、其它答案都不对
已知生成对抗网络的目标函数为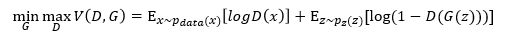 。 则下列描述正确的有
。 则下列描述正确的有
A、无论是生成器,还是判别器,都要使得其取值最大
B、判别器训练阶段,需要使得其取值尽可能大
C、生成器的优化目标是是,使得其取值尽可能地小
D、无论是生成器,还是判别器,都是要使得其取值先变大,后变小




为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 简答题
微信搜一搜
简答题
简答题
微信搜一搜
简答题

 如搜索结果不匹配,请
如搜索结果不匹配,请 














